Dies ist nicht das erste Tutorial zum Erstellen eines Balkendiagramms mit Python und Bokeh. Da es von diesem Plotting-Tool mittlerweile jedoch neue Versionen gibt, war es an der Zeit, in diesem Blog ein weiteres Beispiel zu veröffentlichen. Im Gegensatz zu einem vorherigen Beispiel, wird der Datensatz hier aus einer JSON-Datei gelesen, wobei Pandas zur Anwendung kommt.
Voraussetzung ist zunächst, dass Bokeh installiert wurde:
PS> pip install bokeh # Windows
$ pip3 install bokeh # Linux, macOSIm Vergleich zu älteren Versionen von Bokeh, sind für dieses Beispiel nunmehr folgende Import-Anweisungen erforderlich:
import pandas as pd
from bokeh.plotting import ColumnDataSource
from bokeh.plotting import figure
from bokeh.plotting import show
from bokeh.plotting import output_file
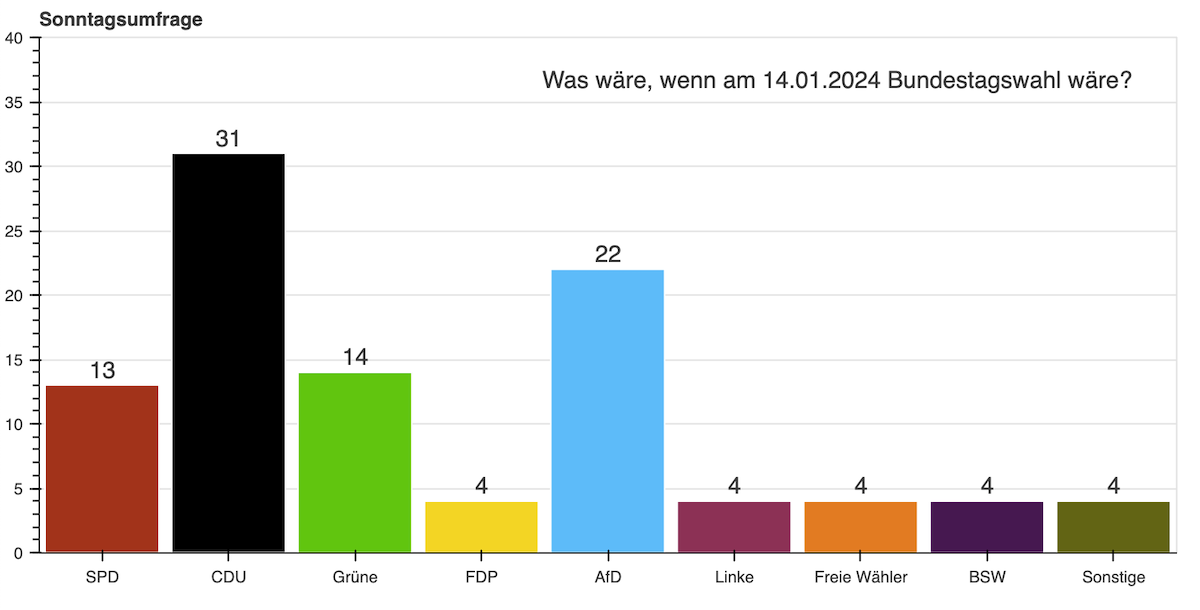
from bokeh.transform import factor_cmapDie zu lesende JSON-Datei sieht wie folgt aus. Es handelt sich dabei um die Umfrageergebnisse zur sogenannten Sonntagswahl (14. Januar 2024), veröffentlicht vom ZDF-Politbarometer.
{
"Partei": {
"0": "SPD",
"1": "CDU",
"2": "Grüne",
"3": "FDP",
"4": "AfD",
"5": "Linke",
"6": "Freie Wähle",
"7": "BSW",
"8": "Sonstige"
},
"Prozent": {
"0": 13,
"1": 31,
"2": 14,
"3": 4,
"4": 22,
"5": 4,
"6": 4,
"7": 4,
"8": 4
}
}Dieser Datensatz wird mit Pandas gelesen. Als Ergebnis erhält man ein Pandas-Dataframe (df):
df = pd.read_json("Umfrage.json")Mit df(info) könnte ich mir nun Infos zum Datensatz anzeigen lassen:
<class 'pandas.core.frame.DataFrame'>
Index: 9 entries, 0 to 8
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Partei 9 non-null object
1 Prozent 9 non-null int64
dtypes: int64(1), object(1)Und mit print(df.to_string()) lassen sich die Daten anzeigen:
Partei Prozent
0 SPD 13
1 CDU 31
2 Grüne 14
3 FDP 4
4 AfD 22
5 Linke 4
6 Freie Wähle 4
7 BSW 4
8 Sonstige 4Als nächstes werden die Werte der Spalten „Partei“ und „Prozent“ in Arrays überführt:
parteien = df["Partei"].values
prozent = df["Prozent"].valuesWir benötigen auch noch die Farbwerte für die Balken:
color = [
"#b72d13",
"#000000",
"#52cf06",
"#f9d91a",
"#4ac5fb",
"#a02d5f",
"#f18019",
"#54125a",
"#6e6f0f",
]Für das Erstellen des Balkendiagramms wird ein ColumnDataSource-Objekt benötigt:
source = ColumnDataSource(data=dict(parties=parties, percent=percent))Außerdem möchte ich mir das Balkendiagramm nicht nur anzeigen lassen, sondern zusätzlich eine HTML-Datei erzeugen. Den Dateinamen für diese Datei lege ich wie folgt fest:
output_file(filename="sonntagsumfrage.html")Dann kann das Balkendiagramm erzeugt werden:
plt = figure(
x_range=parties,
width=800,
height=400,
toolbar_location=None,
title="Sonntagsumfrage",
)
plt.vbar(
x="parties",
top="percent",
width=0.9,
source=source,
line_color="white",
fill_color=factor_cmap("parties", palette=colors, factors=parties),
)
plt.xgrid.grid_line_color = None
plt.y_range.start = 0
plt.y_range.end = 40Der Code ähnelt den bisherigen in diesem Blog gezeigten Beispielen. Es gibt aber einen Unterschied. Zum einen möchte ich keine Legende erzeugen (mit den Prozentangaben), zum anderen soll ein Text hinzugefügt werden.
Da keine Legende hinzugefügt wird, füge ich die Prozentangaben oberhalb der Balken hinzu:
labels = LabelSet(
x="parties",
y="percent",
text="percent",
level="glyph",
text_align="center",
y_offset=5,
source=source,
)Und ein Text wird folgendermaßen erstellt:
question = Label(
x=340,
y=310,
x_units="screen",
y_units="screen",
text="Was wäre, wenn am 14.01.2024 Bundestagswahl wäre?",
# border_line_color="black",
background_fill_color="white",
)Die Zeile border_line_color="black", habe ich auskommentiert, da der Text nicht mit einer Linie umrandet werden soll. Im Grunde wäre sie überflüssig. Diese Zeile habe ich dennoch nicht entfernt, damit man sieht, was für eine Umrandung erforderlich wäre.
Die Prozentangaben und der Text müssen noch hinzugefügt werden. Außerdem sollte nicht die Zeile show(plt) vergessen werden, denn andernfalls öffnet sich der Browser nicht automatisch.
plt.add_layout(labels)
plt.add_layout(question)
show(plt)Zum Schluss nochmal der vollständige Code:
#!/usr/bin/env python3
import pandas as pd
from bokeh.models import ColumnDataSource, Label, LabelSet
from bokeh.plotting import figure, show, output_file
from bokeh.transform import factor_cmap
df = pd.read_json("Umfrage.json")
parties = df["Partei"].values
percent = df["Prozent"].values
colors = [
"#b72d13",
"#000000",
"#52cf06",
"#f9d91a",
"#4ac5fb",
"#a02d5f",
"#f18019",
"#54125a",
"#6e6f0f",
]
source = ColumnDataSource(data=dict(parties=parties, percent=percent))
output_file(filename="sonntagsumfrage.html")
plt = figure(
x_range=parties,
width=800,
height=400,
toolbar_location=None,
title="Sonntagsumfrage",
)
plt.vbar(
x="parties",
top="percent",
width=0.9,
source=source,
line_color="white",
fill_color=factor_cmap("parties", palette=colors, factors=parties),
)
plt.xgrid.grid_line_color = None
plt.y_range.start = 0
plt.y_range.end = 40
labels = LabelSet(
x="parties",
y="percent",
text="percent",
level="glyph",
text_align="center",
y_offset=5,
source=source,
)
question = Label(
x=340,
y=310,
x_units="screen",
y_units="screen",
text="Was wäre, wenn am 14.01.2024 Bundestagswahl wäre?",
# border_line_color="black",
background_fill_color="white",
)
plt.add_layout(labels)
plt.add_layout(question)
show(plt)Diesen Code könnt Ihr als Ausgangspunkt für Eure eigenen Projekte verwenden.
Würde der Datensatz übrigens nicht als JSON-, sondern als CSV-Datei vorliegen, könnte man ihn wie folgt lesen:
df = pd.read_csv("Umfrage.csv", sep=";")Es müsste also nur eine Zeile verändert werden.