Update: Es gibt mittlerweile einen weiteren Artikel zu diesem Thema, der die Bibliothek openpyxl behandelt. Falls Ihr Excel-Dateien mit der Endung „.xlsx“ lesen möchtet, müsst Ihr diese Bibliothek verwenden, da die Entwickler von xlrd den Support für xlsx-Dateien eingestellt haben.
In den bisherigen Python-Tutorials ging es um den Import von Daten aus einer CSV-Datei oder über die URL (sofern der Datensatz online verfügbar war). Nunmehr sollen die Daten aus einer Excel-Datei gelesen werden. Diesmal geht es um die Arbeitslosenzahlen der Stadt Kiel. Diese Daten werden über das Open-Data-Portal der Stadt Kiel zur Verfügung gestellt.
Wie geht man nun vor? Zum einen steht in Python die Bibliothek xlrd zur Verfügung, die über
$ pip install xlrd # Windowsoder
$ pip3 install xlrd # Linux, macOSInstalliert werden kann.
Zum anderen bietet pandas ebenfalls die Möglichkeit, Excel-Dateien zu lesen. Dies erfordert nur eine Zeile Code:
df = pd.read_excel("file_name.xlsx")Update: Seit Dezember 2020 werden nur noch ältere Excel-Dateien mit der Endung „.xls“. unterstützt! Für das Lesen von neueren Excel-Dateien mit der Endung „.xlsx“ kann beispielsweise openpyxl verwendet werden.
Ohne zusätzliche Angaben, wird stets das erste Arbeitsblatt gelesen. Möchte man dies ändern, so kann man folgenden Code verwenden:
df = pd.read_excel("file_name.xlsx", sheetname="sheet_name")In diesem Tutorial möchte ich beide Bibliotheken vorstellen, deswegen werde ich zunächst zeigen, wie xlrd genutzt werden kann. Anschließend folgt der Code für das Lesen der Excel-Datei mit pandas. Da ich Daten in der Regel sowieso mit pandas lese, um sie anschließend grafisch darzustellen, ist die Verwendung von xlrd hier im Grunde überflüssig. Nichtsdestotrotz stelle ich hier zunächst xlrd der Vollständigkeit halber vor.
Die Excel-Datei habe ich übrigens aus der CSV-Datei, die von der Stadt Kiel bereitgestellt wird, erzeugt.
Daten lesen mit xlrd
Beginnen wir damit, die erforderlichen Bibliotheken zu importieren:
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import xlrdEs folgt das Einlesen der Excel-Datei (mit xlrd):
DATA_FILE = "data/kiel_arbeitslose.xlsx"
# Read Excel data
def read_excel_file(filename):
book = xlrd.open_workbook(filename, encoding_override = "utf-8")
sheet = book.sheet_by_index(0)
x_data = np.asarray([sheet.cell(i, 0).value for i in range(1, sheet.nrows)])
y_data = np.asarray([sheet.cell(i, 1).value for i in range(1, sheet.nrows)])
return x_data, y_data
x_data, y_data = read_excel_file(DATA_FILE)Der Konstanten DATA_FILE wird zunächst der Dateipfad zugewiesen.
Die Funktion read_excel_file(filename) erledigt sodann die eigentliche Arbeit. Über die Zeile
book = xlrd.open_workbook(filename, encoding_override = "utf-8")wird die zu verwendende Excel-Datei festgelegt.
Excel-Dateien bestehen aus mehreren Arbeitsblättern (sheets). Da sich die Daten im ersten Arbeitsblatt (Index 0) befinden, kann dies der Variablen sheet folgendermaßen zugewiesen werden:
sheet = book.sheet_by_index(0)In diesem Arbeitsblatt benötigen wir die Daten aus der ersten und zweiten Spalte (Jahr und Arbeitslose) als numpy-Array:
x_data = np.asarray([sheet.cell(i, 0).value for i in range(1, sheet.nrows)])
y_data = np.asarray([sheet.cell(i, 1).value for i in range(1, sheet.nrows)])Der Aufruf der Funktion erfolgt schließlich mit
x_data, y_data = read_excel_file(DATA_FILE)Nun sollen diese Daten noch mit matplotlib visualisiert werden, wobei ein Pandas-Dataframe genutzt wird. Da ich diesen Code bereits in den vorhergehenden Python-Tutorials erläutert habe, erspare ich mir hier weitere Ausführungen.
# Create a Pandas Dataframe
df = pd.DataFrame({'x':x_data, 'y':y_data})
# print the first five rows
print(df.head())
df_cleaned = df.dropna(how='all')
df_years = df_cleaned['x'].astype(np.uint16)
x = df_years.values
y = df_cleaned['y'].values # no value for 1993
fig, ax = plt.subplots()
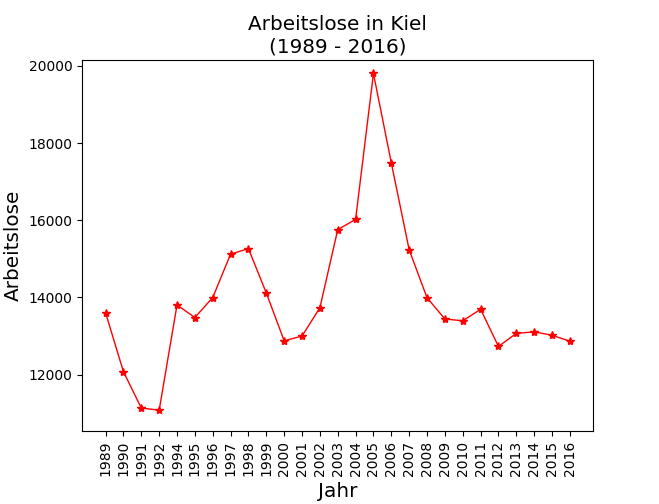
plt.title("Number of Unemployed in Kiel\n(1989 - 2016)", size="x-large")
plt.ylabel("Unemployed", size="x-large")
plt.xlabel("Year", size="x-large")
plt.plot(y, "r*-", markersize=6, linewidth=1, color='r')
ax.set_xticks(range(len(x)))
ax.set_xticklabels(x, rotation='vertical')
plt.show()Daten mit pandas lesen
Wie bereits gesagt, ist der Weg über xlrd in diesem Beispiel überflüssig, da hier sowieso pandas genutzt wird. Deswegen nun der Code ohne den Umweg über xlrd:
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
DATA_FILE = "data/kiel_arbeitslose.xlsx"
# Create a Pandas Dataframe
# (read the Excel data with Pandas)
df = pd.read_excel(DATA_FILE)
# print the first five rows
print(df.head())
df_cleaned = df.dropna(how='all')
df_years = df_cleaned['Jahr'].astype(np.uint16)
x = df_years.values
y = df_cleaned['Arbeitslose'].values # no value for 1993
fig, ax = plt.subplots()
plt.title("Arbeitslose in Kiel\n(1989 - 2016)", size="x-large")
plt.ylabel("Arbeitslose", size="x-large")
plt.xlabel("Jahr", size="x-large")
plt.plot(y, "r*-", markersize=6, linewidth=1, color='r')
ax.set_xticks(range(len(x)))
ax.set_xticklabels(x, rotation='vertical')
plt.show()Diesen Code findet Ihr übrigens — zusammen mit dem Code zu anderen Python-/Jupyter-Projekten — in meinem Github Repository Kiel_Open_Data.
Zuletzt aktualisiert am 21. Januar 2022