Mit Pandas können nicht nur unterschiedliche Dateiformate gelesen werden, es ist auch möglich einen Datensatz (DataFrame) als Excel-Datei zu speichern. Dies erledigt eine Zeile Code:
df.to_excel('data.xlsx')Darüber hinaus versteht sich Pandas aber auch noch mit weiteren Dateiformaten:
to_csv()
to_json()
to_html()Betrachten wir dies an einem Beispiel. Nachfolgende Zeilen Code rufen Daten mit requests ab und lesen den Datensatz (CSV-Format) mit pd.read_csv(). Als Ergebnis erhalten wir ein Pandas DataFrame. Bei den Daten, die in diesem Beispiel abgerufen werden, handelt es sich übrigens um die Anzahl der Studierenden in Kiel.
#!/usr/bin/env python3
import io
import requests
import pandas as pd
import matplotlib.pyplot as plt
CSV_URL = "https://www.kiel.de/opendata/kiel_bildung_wissenschaft_universitaet_fachhochschule_studierende.csv"
# Fetch data
csv_data = requests.get(CSV_URL).content
# Read data
df = pd.read_csv(io.StringIO(csv_data.decode("utf-8")), sep=";")Die Daten können mit print(df) ausgegeben werden. Möchte man nur die ersten fünf Zeilen angezeigt bekommen, ist print(df.head(5)) zu verwenden. Und die letzten fünf Zeilen lassen sich mit print(df.tail(5)) anzeigen.
Der Datensatz könnte nun in unterschiedliche Formate exportiert werden:
df.to_excel("students.xlsx")
df.to_csv("students.csv")
df.to_json("students.json")
df.to_html("students.html")Darüber hinaus kann der Datensatz mit matplotlib visualisiert werden, wobei ich hier lediglich die Werte der Spalte „Studierende insgesamt“ verwende:
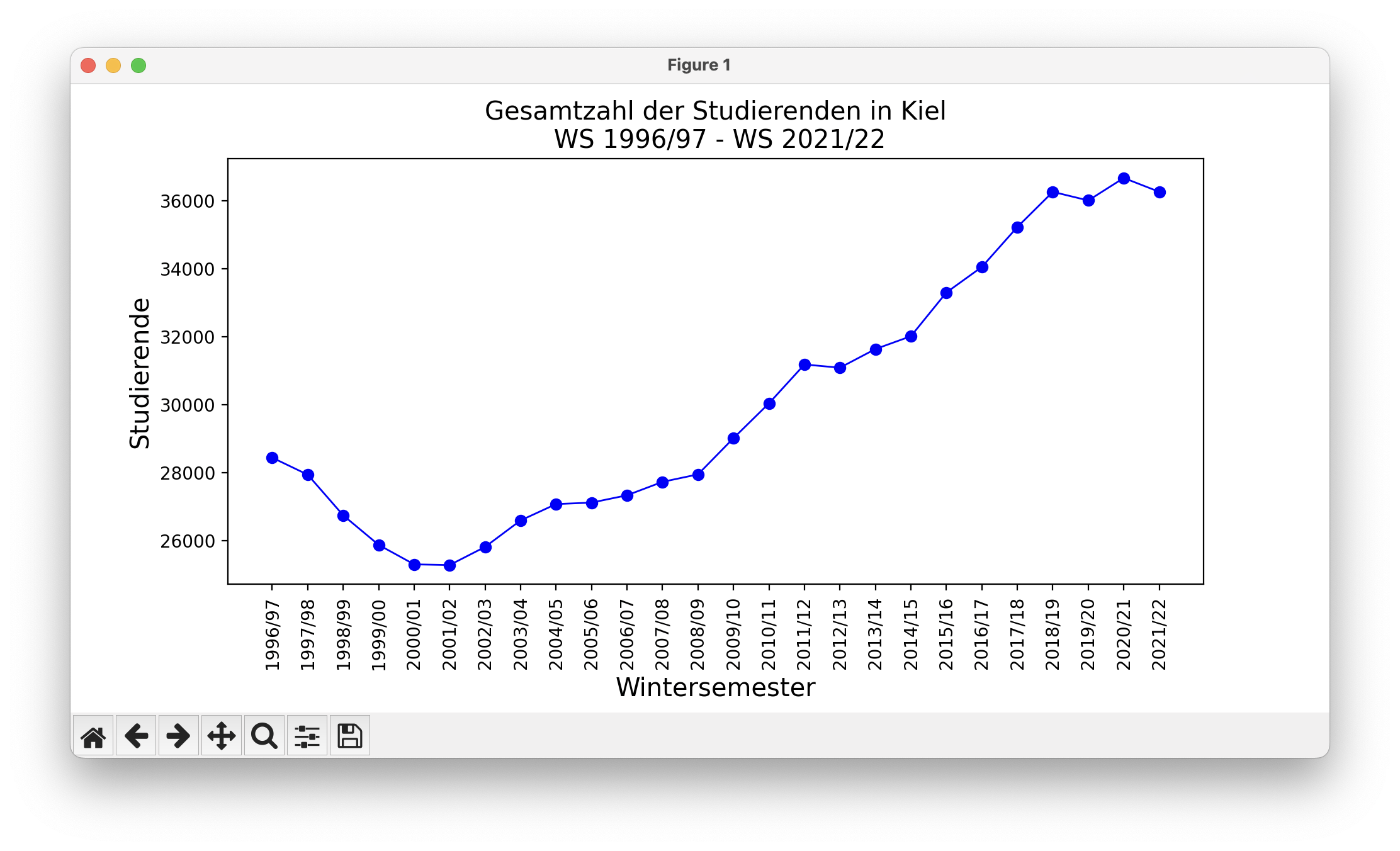
fig, ax = plt.subplots()
x = df["Wintersemester"]
y = df["Studierende insgesamt"]
plt.title("Gesamtzahl der Studierenden in Kiel\n WS 1996/97 - WS 2021/22", size="x-large")
plt.ylabel("Studierende", size="x-large")
plt.xlabel("Wintersemester", size="x-large")
plt.plot(y, "o-", markersize=6, linewidth=1, color="b")
ax.set_xticks(range(len(x)))
ax.set_xticklabels(x, rotation="vertical")
plt.show()