Bevor es an die Visualisierung von Daten geht, müssen diese häufig noch für die weitere Visualisierung (oder Datenanalyse) vorbereitet werden. Das kann beispielsweise daran liegen, dass das vorliegende Datenformat problematisch ist oder dass im Datenbestand Daten fehlen. Im folgenden Beispiele möchte ich Schritt für Schritt zeigen, wie man an bestimmte Probleme herangehen kann, genauer gesagt geht es hier um
- Probleme mit der Zeichenkodierung,
- um fehlende Werte (Stichwort:
NaN= Not a Number) und - um die Darstellung von Jahreszahlen auf der x-Achse.
Daten vorbereiten
Ausgangspunkt für die nachfolgenden Ausführungen ist ein Datensatz zu Ehescheidungen, den ich vom Open-Data-Portal der Stadt Kiel heruntergeladen haben. Dies Daten habe ich leicht modifiziert. So fehlen zwei Werte sowie die erste Zeile mit den Überschriften.
Zum vollständigen – nicht modifizierten – Datensatz hatte ich übrigens bereits einen Beitrag veröffentlicht, den Ihr hier lesen könnt.
Beginnt nun mit einer neuen Python Datei; meine habe ich “kiel_ehescheidungen.py” genannt. Alternativ könnt Ihr auch ein Jupyter Notebook nutzen.
Zunächst importieren wir das Modul Pandas:
import pandas as pdDann wollen wir die modifizierte CSV-Datei lesen. Sie heißt “kiel_ehescheidungen_modified.csv” und kann hier heruntergeladen werden. Die Originaldatei findet Ihr übrigens auf dieser Internetseite der Stadt Kiel. Außerdem sollen die ersten fünf Zeilen ausgegeben werden:
df = pd.read_csv("kiel_ehescheidungen_modified.csv")
print(df.head())Wenn Ihr den Code ausführt, werdet Ihr eine Überraschung erleben. Es erscheint eine Fehlermeldung, bei der unter anderem eine Info ähnlich der folgenden ausgegeben wird: “UnicodeDecodeError: ‚utf-8‘ codec can’t decode byte 0xf6 in position 19: invalid start byte”.
Anhand von “UnicodeDecodeError: utf-8” läßt sich vermuten, dass es ein Problem mit der Zeichenkodierung gibt. Und wenn Ihr die Datei in einem Editor öffnet (zum Beispiel in Sublime Text), bestätigt sich dieser Verdacht. Denn als Zeichenkodierung wird “Western (Windows 1252)” angezeigt und nicht UTF-8 (was von Pandas standardmäßig gefordert wird). Abhilfe schafft hier die Angabe der verwendeten Zeichenkodierung. In der Praxis erweist sich meistens ein Aufruf mit encoding='latin1', encoding='iso-8859-1' oder encoding='cp1252' als hilfreich.
Wir probieren hier encoding='latin1' aus. Außerdem weise ich den Dateinamen einer Variablen csv_data zu. Der Code sieht jetzt wie folgt aus:
import pandas
csv_data = "kiel_ehescheidungen_modified.csv"
df = pd.read_csv(csv_data, encoding='latin1')
print(df.head())Die Ausgabe sieht schon besser aus:
de-sh;Kiel;2000;Bevölkerung;Ehescheidungen;834
0 de-sh;Kiel;2001;Bevölkerung;Ehescheidungen;
1 de-sh;Kiel;2002;Bevölkerung;Ehescheidungen;822
2 de-sh;Kiel;2003;Bevölkerung;Ehescheidungen;802
3 de-sh;Kiel;2004;Bevölkerung;Ehescheidungen;800
4 de-sh;Kiel;2005;Bevölkerung;Ehescheidungen;762Aber wie Ihr sehen könnt, wird die erste Werte-Zeile als Überschriften-Zeile interpretiert. Dies ändern wir sogleich, indem die Überschriften der Spalten als Liste übergeben werden. Außerdem wird mit header=None angegeben, dass der Datensatz keine Überschriften-Zeile hat.
df = pd.read_csv(csv_data,
encoding='latin1',
header=None,
names=['Land', 'Stadt', 'Jahr', 'Kategorie', 'Merkmal', 'Ehescheidungen'])Das Ergebnis ist aber immer noch seltsam aus:
Land ... Ehescheidungen
0 de-sh;Kiel;2000;Bevölkerung;Ehescheidungen;834 ... NaN
1 de-sh;Kiel;2001;Bevölkerung;Ehescheidungen; ... NaN
2 de-sh;Kiel;2002;Bevölkerung;Ehescheidungen;822 ... NaN
3 de-sh;Kiel;2003;Bevölkerung;Ehescheidungen;802 ... NaN
4 de-sh;Kiel;2004;Bevölkerung;Ehescheidungen;800 ... NaNDies hängt damit zusammen, dass zusätzlich noch angegeben werden muss, dass die Werte durch Semikolons getrennt werden. Ändert man den Code also zu
csv_data = 'kiel_ehescheidungen_modified.csv'
df = pd.read_csv(csv_data, encoding='latin1',
sep=';',
header=None,
names=['Land', 'Stadt', 'Jahr', 'Kategorie', 'Merkmal', 'Ehescheidungen'])
print(df.head())sieht das Ergebnis endlich gut aus:
Land Stadt Jahr Kategorie Merkmal Ehescheidungen
0 de-sh Kiel 2000 Bevölkerung Ehescheidungen 834.0
1 de-sh Kiel 2001 Bevölkerung Ehescheidungen NaN
2 de-sh Kiel 2002 Bevölkerung Ehescheidungen 822.0
3 de-sh Kiel 2003 Bevölkerung Ehescheidungen 802.0
4 de-sh Kiel 2004 Bevölkerung Ehescheidungen 800.0In der Zeile mit dem Index 1 erkennen wir sogleich auch das nächste Problem: NaN. Dies steht für “Not a Number”, mit anderen Worten: Hier fehlt ein Wert. Des Weiteren benötigen wir lediglich zwei Spalten: Das Jahr (x-Achse) und die Anzahl der Ehescheidungen (y-Achse).
Fangen wir damit an, die Bibliothek matplotlib zu importieren:
import matplotlib.pyplot as pltAls nächstes kümmern wir uns um die nicht vorhandenen Werte. Folgender Code entfernt die Zeilen, in denen ein Wert fehlt:
df_cleaned = df.dropna()Dies ist zwar nicht zwangsläufig notwendig, aber so erhalten wir ein Liniendiagramm mit einer einheitlichen Linie. Würden wir die Zeilen nicht entfernen, dann wäre die Linie in der grafischen Darstellung unterbrochen.
Diese bereinigten Daten, genauer gesagt das Jahr und die Anzahl der Ehescheidungen, können nun den Variablen x (für die x-Achse) und y (für die y-Achse) zugewiesen werden.
x = df_cleaned['Jahr'].values
y = df_cleaned['Ehescheidungen'].valuesDaten visualisieren
Kommen wir zur Visualisierung. Hierfür benötigen wir lediglich folgende zwei Zeilen:
plt.plot(x, y)
plt.show()Bevor wir aber einen Blick auf das erzeugte Liniendiagramm werfen, zeige ich zunächst den bisherigen Code:
import pandas as pd
import matplotlib.pyplot as plt
csv_data = 'kiel_ehescheidungen_modified.csv'
df = pd.read_csv(csv_data, encoding='latin1', sep=';', header=None,
names=['Land', 'Stadt', 'Jahr', 'Kategorie', 'Merkmal', 'Ehescheidungen'])
print(df.head())
df_cleaned = df.dropna()
x = df_cleaned['Jahr'].values
y = df_cleaned['Ehescheidungen'].values
plt.plot(x, y)
plt.show()Dadurch erhalten wir folgende Grafik…
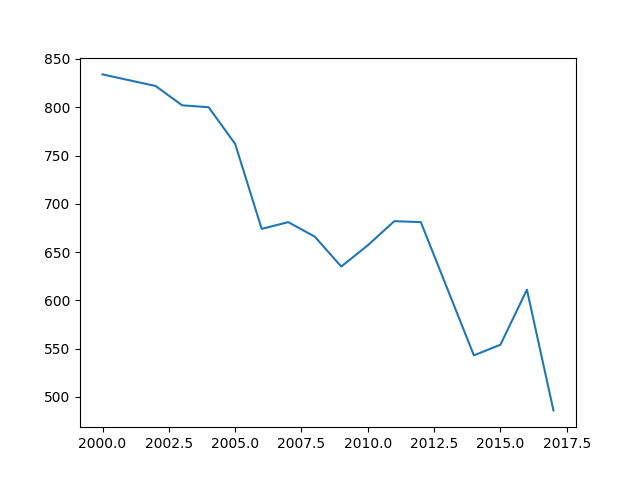
… und müssen feststellen, das die Jahreszahlen als Kommazahlen dargestellt werden, was schon seltsam aussieht. Außerdem wurden scheinbar irgendwelche Jahreszahlen willkürlich ausgewählt 2000.0 bis 2017.5). Das ist nicht das Ergebnis, das wir uns wünschen.
Um mehr Einfluss auf die grafische Darstellung zu erhalten, nutzen wir deswegen ein Subplot
fig, ax = plt.subplots()und können dadurch die x-Achse festlegen:
ax.set_xticks(range(len(x)))Da wir zahlreiche Jahreszahlen haben, bietet es sich an, diese vertikal anzeigen zu lassen:
ax.set_xticklabels(x, rotation='vertical')Schließlich folgt noch
plt.plot(y)
plt.show()und es erscheint diese Darstellung:
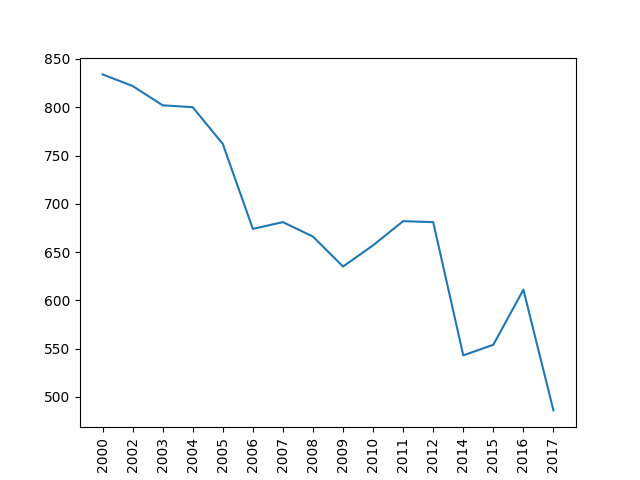
Um nicht den Überblick zu verlieren, hier nochmal der bisherige Code:
import pandas as pd
import matplotlib.pyplot as plt
csv_data = 'kiel_ehescheidungen_modified.csv'
df = pd.read_csv(csv_data, encoding='latin1', sep=';', header=None,
names=['Land', 'Stadt', 'Jahr', 'Kategorie', 'Merkmal', 'Ehescheidungen'])
print(df.head())
df_cleaned = df.dropna()
x = df_cleaned['Jahr'].values
y = df_cleaned['Ehescheidungen'].values
# Ein Subplot erzeugen
fig, ax = plt.subplots()
# Die x-Achse festlegen
ax.set_xticks(range(len(x)))
ax.set_xticklabels(x, rotation='vertical')
plt.plot(y). # Nur y übergeben!
plt.show()Damit sind wir im Grunde fertig! Aber ich möchte zum Abschluss noch zeigen, wie Beschriftungen hinzugefügt werden können. Außerdem soll die Darstellung der Linie noch verändert werden.
Was die Beschriftungen angeht, dies ist schnell mit
plt.title("Ehescheidungen in Kiel", size="x-large")
plt.ylabel("Anzahl", size="x-large")
plt.xlabel("Jahr", size="x-large")umgesetzt.
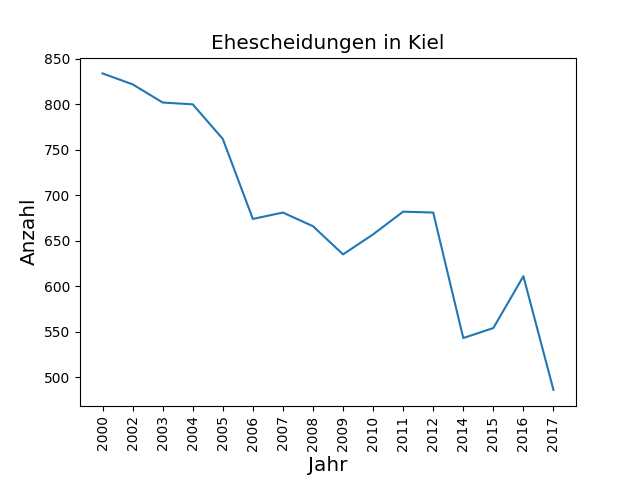
Und die Darstellung der Linie kann beispielsweise mit
plt.plot(y, "r*-", markersize=6, linewidth=1, color='b')angepasst werden.
Außerdem ließe sich eine Legende wie folgt realisieren (wobei dies bei einer Linie nur wenig Sinn macht):
plt.plot(y, "r*-", markersize=6, linewidth=1, color='r', label="Scheidungen")
plt.legend(loc=(0.6, 0.8))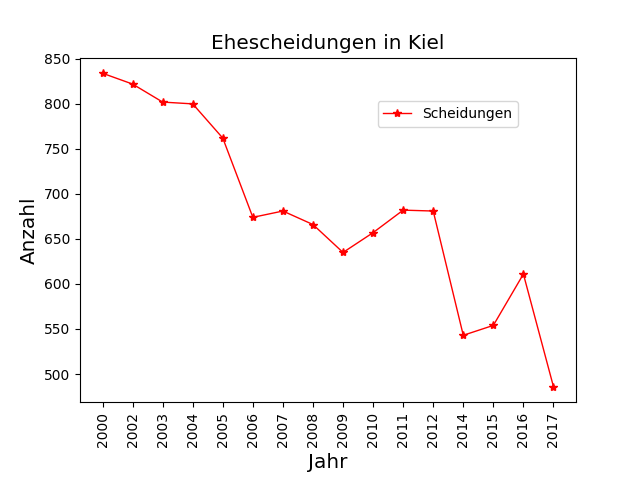
Der komplette Code sieht schließlich so aus:
#!/usr/bin/env python3
'''
Ehescheidungen in Kiel
Der vollständige Datensatz wird im Open-Data-Portal der Stadt Kiel zum Download bereitgestellt:
https://www.kiel.de/opendata/kiel_bevoelkerung_ehescheidungen.csv
Version: 1.0
Python 3.7
Date created: 25.02.2019
'''
# Bibliotheken importieren
import pandas as pd
import matplotlib.pyplot as plt
# CSV-Datei lesen (Dataframe => df) erzeugen
csv_data = 'kiel_ehescheidungen_modified.csv'
df = pd.read_csv(csv_data, encoding='latin1', sep=';', header=None,
names=['Land', 'Stadt', 'Jahr', 'Kategorie', 'Merkmal', 'Ehescheidungen'])
# Die ersten fünf Zeilen ausgeben
print(df.head())
# Zeilen mit fehlenden Werten (NaN) entfernen
df_cleaned = df.dropna()
x = df_cleaned['Jahr'].values
y = df_cleaned['Ehescheidungen'].values
# Subplot erstellen
fig, ax = plt.subplots()
# Beschriftungen hinzufügen
plt.title("Ehescheidungen in Kiel", size="x-large")
plt.ylabel("Anzahl", size="x-large")
plt.xlabel("Jahr", size="x-large")
# Aussehen der x-Achse festlegen
ax.set_xticks(range(len(x)))
ax.set_xticklabels(x, rotation='vertical')
# y-Achse, Legende
plt.plot(y, "r*-", markersize=6, linewidth=1, color='r', label="Scheidungen")
plt.legend(loc=(0.6, 0.8))
plt.show()Hinsichtlich der Art der Darstellung gibt es selbstverständlich noch weitere Optionen, die Ihr der Dokumentation von matplotlib entnehmen könnt.