Aktualisiert am 12. Juli 2021
Das Bundesland Schleswig-Holstein hat jetzt ebenfalls ein Open-Data-Portal. Leider sind die Datenformate recht unterschiedlicher Art (xls, xlsx, pdf, txt, wfs, etc.). Immerhin stehen aber derzeit 236 Datensätze als CSV-Dateien zur Verfügung, ein Dateityp, der sich gut lesen läßt. Um zu demonstrieren, wie man dies mit Python machen kann, habe ich mir die Daten zu Passagieren nach Ziel und Herkunft im Kieler Hafen ausgesucht.
Ich nutze nachfolgend ein Jupyter Notebook. Außerdem müssen folgende Module installiert sein:
- matplotlib
- numpy
- pandas
Die Datei mit den Daten habe ich umbenannt zu „kiel_transport_hafen.csv“. Sie befindet sich bei mir in einem Unterverzeichnis „datasets“, so dass der zu verwendende Pfad „datasets/kiel_transport_hafen.csv“ lautet.
Zunächst der Code zum Lesen der CSV-Datei:
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
FILEPATH = "datasets/kiel_transport_hafen.csv"
# read csv dataset
df = pd.read_csv(FILEPATH, sep=';')
# show the first five rows
print(df.head())Wenn Ihr diesen Code ausführt, gibt es jedoch eine Überraschung: Es erscheint unter anderem die Fehlermeldung:
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xe4 in position 1: invalid continuation byteDas hängt damit zusammen, dass Python 3 bzw. die Methode read_csv() standardmäßig UTF-8 als Zeichenkodierung erwartet. Die heruntergeladene Datei nutz aber Windows 1552. Deswegen muss als weiteres Argument encoding='cp1252' übergeben werden, so dass der „richtige“ Code wie folgt aussieht:
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
FILEPATH = "datasets/kiel_transport_hafen.csv"
# read csv dataset
df = pd.read_csv(FILEPATH, encoding='cp1252', sep=';')
# show the first five rows
print(df.head())Den weiteren Code werde ich nicht weiter kommentieren, sondern verweise auf meine anderen Blogbeiträge zur Datenvisualisierung mit Python. Ich möchte nur auf eine Sache hinweisen: Die Zeile
df_cleaned = df.dropna()ist nicht zwangsläufig erforderlich. Bei meinem Code ist sie aber in der Regel vorhanden, um Zeilen, die keinen Wert enthalten, zu verwerfen. So erhält man stets ein Liniendiagramm mit einer einheitlichen Linie.
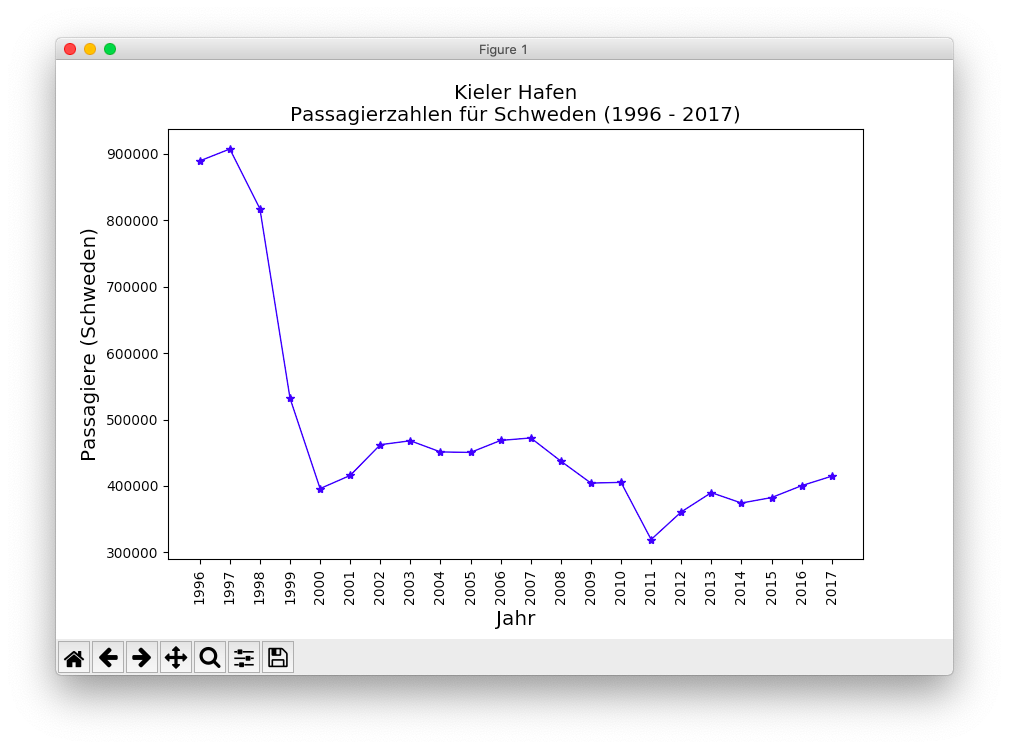
Außerdem beschränke ich die Darstellung auf die Passagierzahlen für Schweden.
df_cleaned = df.dropna()
df_years = df_cleaned['Jahr'].astype(np.uint16)
df_sweden = df_cleaned['Schweden']
x = df_years.values
y = df_sweden.values
fig, ax = plt.subplots()
plt.title('Kieler Hafen\nPassagierzahlen für Schweden (1996 - 2017)', size='x-large')
plt.ylabel('Passagiere (Schweden)', size="x-large")
plt.xlabel('Jahr', size='x-large')
plt.plot(y, '*-', markersize=6, linewidth=1, color='b')
ax.set_xticks(range(len(x)))
ax.set_xticklabels(x, rotation='vertical')
plt.show()Dieser Code ist zusammen mit weiteren Beispielen bei Github verfügbar.
Zuletzt aktualisiert am 12. Juli 2021