In der Vergangenheit hatte ich gezeigt, wie mit Python Daten, die im JSON-Format vorliegen, aus dem Internet abgerufen werden können. In diesem Beispiel möchte ich anhand des Datenportals Eurostat näher auf diesem Thema, also auf REST, JSON zusammen mit Python eingehen. Dazu soll auf den Datenbestand von Eurostat zugegriffen werden.
Um von Eurostat Daten laden zu können, muss man die entsprechende URL kennen. Diese URL besteht aus einem statischen und einen dynamischen Teil. Für die Version 2.1 lautet der statische Teil:
https://ec.europa.eu/eurostat/wdds/rest/data/v2.1Interessant ist hieran die Abkürzung „rest“. Dies steht für REpresentational State Transfer und ist der de-facto Standard einer Softwarearchitektur, die dazu dient, Daten über das Internet, genauer gesagt des World Wide Web, bereitzustellen. Mit anderen Worten: Mit REST wird eine Art der Kommunikation zwischen Client und Server definiert. Dabei bedient sich diese Softwarearchitektur standardisierten Verfahren/Formaten (z.B. JSON, XML oder HTTPS). Ein Dienst, der diesen Standards folgt, wird auch als RESTful bezeichnet.
Nach dem statischen Teil folgt der dynamische Teil der URL. Ein Blick zeigt sofort, dass hier das Format JSON verwendet wird.
https://ec.europa.eu/eurostat/wdds/rest/data/v2.1/jsonEs folgt die Sprache, beispielsweise „en“ für englisch, und schließlich der Datensatz. Für dieses Beispiel habe ich eine Statistik zur Population herausgesucht: „Child and youth population on 1 January by sex and age“. Dieser hat den Datensatz-Code: yth_demo_010, was zu folgender URL führt:
https://ec.europa.eu/eurostat/wdds/rest/data/v2.1/json/en/yth_demo_010Die Datensatz-Codes können übrigens über die Database-Seiten von Eurostat in Erfahrung gebracht werden. Für dieses Beispiel finden sich die Codes auf dieser Internetseite.
Die Eingabe der Adresse im Firefox-Browser führt jetzt zu folgender Ansicht:
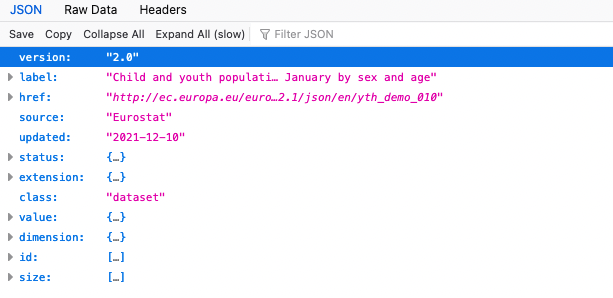
Der Firefox-Browser ist in der Lage die JSON-Daten formatiert darzustellen. Alternativ dazu führt ein Klick auf „Rohdaten“ (oder: „Raw Data“) zur nicht-formatierten Ansicht.
{"version":"2.0","label":"Child and youth population on 1 January by sex and age","href":"http://ec.europa.eu/eurostat/wdds/rest/data/v2.1/json/en/yth_demo_010","source":"Eurostat","updated":"2021-12-10","status":
...
}Was ist REST?
Die URL, über die die Daten zum Abruf bereitgestellt werden, kennen wir jetzt. Werfen wir nun einen Blick hinter die Kulissen. Genauer gesagt sehen wir uns REST an, also den hier verwendeten Architektur-Style der API (Application Programming Interface).
REST wurde Anfang der 2000er entwickelt und ist ein Webstandard für eine Client-Server-Architektur. Dabei wird häufig nicht nur eine Resource für den Abruf bereitgestellt, sondern es kann für den Client auch die Möglichkeit bestehen, verschiedene Aktionen auszuführen, zum Beispiel Daten hinzuzufügen oder bestehende Daten zu verändern. Die Aktionen, die vom Server ausgeführt werden sollen, werden als HTTP-Methoden (auch: verbs) bezeichnet. Die wichtigsten Methoden sind GET, POST, PUT und DELETE.
Daten mit Python abrufen
In diesem Beispiel geht es darum, Daten vom Eurostat-Server abzurufen, mithin eine GET-Methode anzuwenden. Um dies umzusetzen zu können, wird die URL zum Endpunkt benötigt. Wie bereits erwähnt, lautet sie in unseren Fall
https://ec.europa.eu/eurostat/wdds/rest/data/v2.1/json/en/yth_demo_010Dadurch werden die Daten im JSON-Format zum Abruf bereitgestellt. So einfach ist es aber nicht immer. Häufig werden die Datensätze sehr umfangreich sein, was zu einer Fehlermeldung führt. Darüber hinaus mag es sein, dass nicht alle Daten benötigt werden. Vielleicht sind nur die Werte für ein bestimmtes Jahr relevant. Es kommen dann Filter ins Spiel. Sie sind Bestandteil des dynamischen Teils der URL und präzisieren den exakten Endpunkt für die Abfrage.
Doch welche Filter stehen zur Verfügung? Eurostat erklärt auf dieser Internetseite die generelle API-Struktur für die Durchführung einer REST-Anfrage. Damit lässt sich in der Regel aber noch nicht viel anfangen. Denn es fehlen die konkreten Filter für den entsprechenden Datensatz. Erfreulicherweise gibt es einen Query Builder. Nach der Eingabe der Bezeichnung des Datensatzes, werden die zur Verfügung stehenden Filteroptionen angezeigt. Für unser Beispiel muss der Dataset-Code yth_demo_010 eingegeben werden. Dies führt zu folgender Auswahlmöglichkeit:
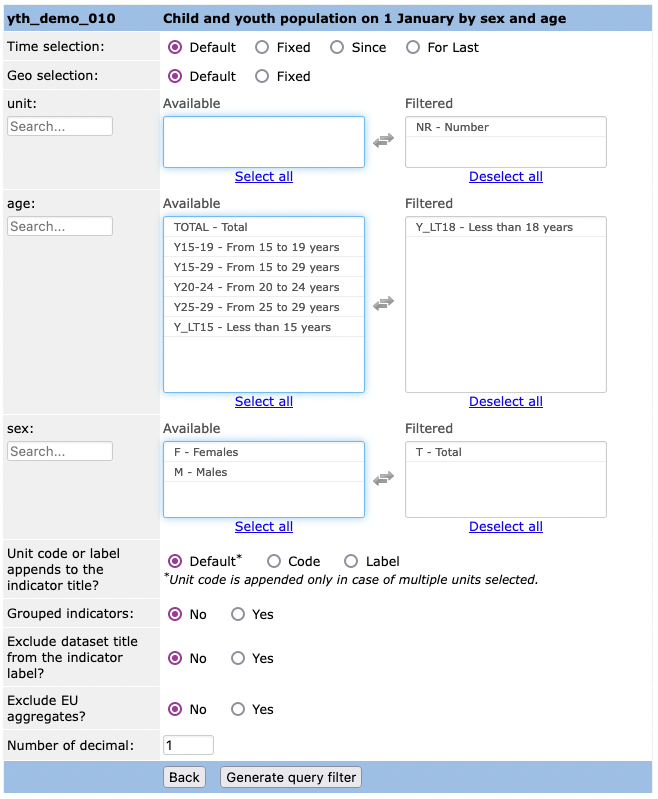
Ein Klick auf „Generate query filter“ zeigt jetzt den datasetCode zusammen mit dem optionalen Teil, den Filtern, an. Dieser wird an die URL angehängt, so dass die komplette Struktur wie folgt aussieht:
https://ec.europa.eu/eurostat/wdds/rest/data/v2.1/json/en/yth_demo_010?precision=1&sex=T&unit=NR&age=Y_LT18&time=2020Damit der Datensatz übersichtlich bleibt, habe ich übrigens zusätzlich das gewünschte Jahr (&time=2020) angefügt.
Daten mit Python abrufen
Für diese Aufgabe kommt requests zum Einsatz.
import requestsBevor aber die Abfrage durchgeführt werden kann, gilt es die URL zu erstellen, wobei ich eine Trennung zwischen dem statischen Teil plus dem Dataset-Code und dem optionalen Teil, also den Filtern, vorgenommen habe.
url_with_dataset = "https://ec.europa.eu/eurostat/wdds/rest/data/v2.1/json/en/yth_demo_010"
filters = "?precision=1&sex=T&unit=NR&age=Y_LT18&time=2020"
url = url_with_dataset + filtersDie eigentliche Ausführung von requests stellt jetzt keine große Herausforderung dar und könnte z.B. so aussehen:
def fetch_data_from_eurostat():
response = requests.get(url).content
return response.json()
def main():
rval = fetch_data_from_eurostat()
print(rval)
if __name__ == '__main__':
main()Nun kann nicht davon ausgegangen werden, dass die Abfrage immer funktioniert. Es mag sein, dass der Server ausgefallen ist oder das sich die URL geändert hat. Deswegen ist es empfehlenswert, eine Ausnahmebehandlung hinzuzufügen. Der komplette Code könnte dann so aussehen:
import sys
import requests
url_with_dataset = "https://ec.europa.eu/eurostat/wdds/rest/data/v2.1/json/en/yth_demo_010"
filters = "?precision=1&sex=T&unit=NR&age=Y_LT18&time=2020"
url = url_with_dataset + filters
response = None
def fetch_data_from_eurostat():
global response
try:
response = requests.get(url, timeout=5)
except requests.Timeout as e:
sys.exit(f"Unable to retrieve data:\n{e!r}")
except requests.ConnectionError as e:
sys.exit(f"Unable to retrieve data:\n{e!r}")
if response.status_code == 200:
print("Status 200, OK")
return response.json()
else:
sys.exit("JSON data request not successfull (wrong status code)!")
def main():
rval = fetch_data_from_eurostat()
print(rval)
if __name__ == '__main__':
main()Mit
except requests.Timeout as e:wird dem Umstand einer Zeitüberschreitung Rechnung getragen, während
except requests.ConnectionError as e:bei einem Verbindungsfehler ausgeführt wird. Dies könnte beispielsweise bei einer schlechten oder nicht vorhandenen Internetverbindung der Fall sein.
Darüber hinaus sollen nur dann die empfangenen Daten zurückgegeben werden, wenn der Status-Code 200 vorliegt:
if response.status_code == 200:
print("Status 200, OK")
return response.json()Hinsichtlich der Ausgabe der empfangenen Daten kann auch noch eine Verbesserung vorgenommen werden. Mit pprint lassen sich Datenstrukturen besser darstellen. Hierfür muss zunächst eine weitere Importanweisung hinzugefügt werden:
from pprint import pprintDie Zeile
print(rval)kann dann durch
pprint(rval)ersetzt werden.