Im ersten Artikel zu Ollama wurde erklärt, wie Ollama auf dem Mac installiert werden kann, um eine KI lokal nutzen zu können. Nun wollen wir einen genaueren Blick auf die Möglichkeiten werfen, die dieses KI-Werkzeug bietet.
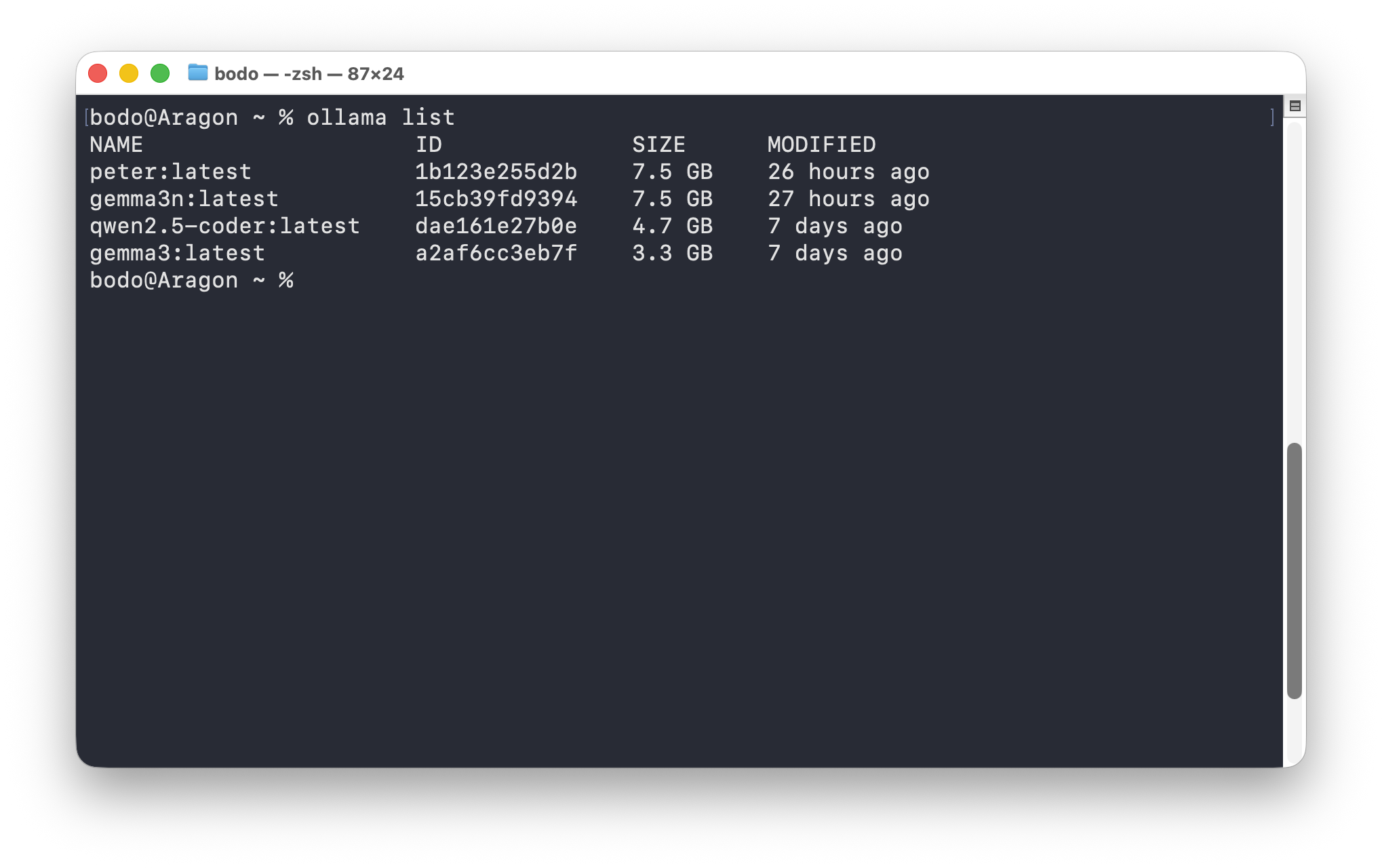
Befassen wir uns zunächst mit den zur Verfügung stehenden Sprachmodellen (lokal und online). Einen Überblick über bereits installierten, also lokal ausführbaren Modellen, liefert die Option list:
% ollama listSofern bereits Modelle installiert wurden, erscheint eine Rückmeldung ähnlich der folgenden Ausgabe:
NAME ID SIZE MODIFIED
qwen2.5-coder:latest dae161e27b0e 4.7 GB 6 days ago
gemma3:latest a2af6cc3eb7f 3.3 GB 6 days agoIn diesem Beispiel sind zwei Modelle aufgeführt:
- qwen2.5-coder und
- gemma3
Welche Modelle heruntergeladen werden können, verrät Ollamas Internetseite. Ruft man dort die Details zu gemma3 auf, erfährt man, dass es sich bei der Version „latest“ um die Version gemma3:4b handelt, die 3,3 GB groß ist und als Eingabe sowohl Text als auch Bilder zuläßt.
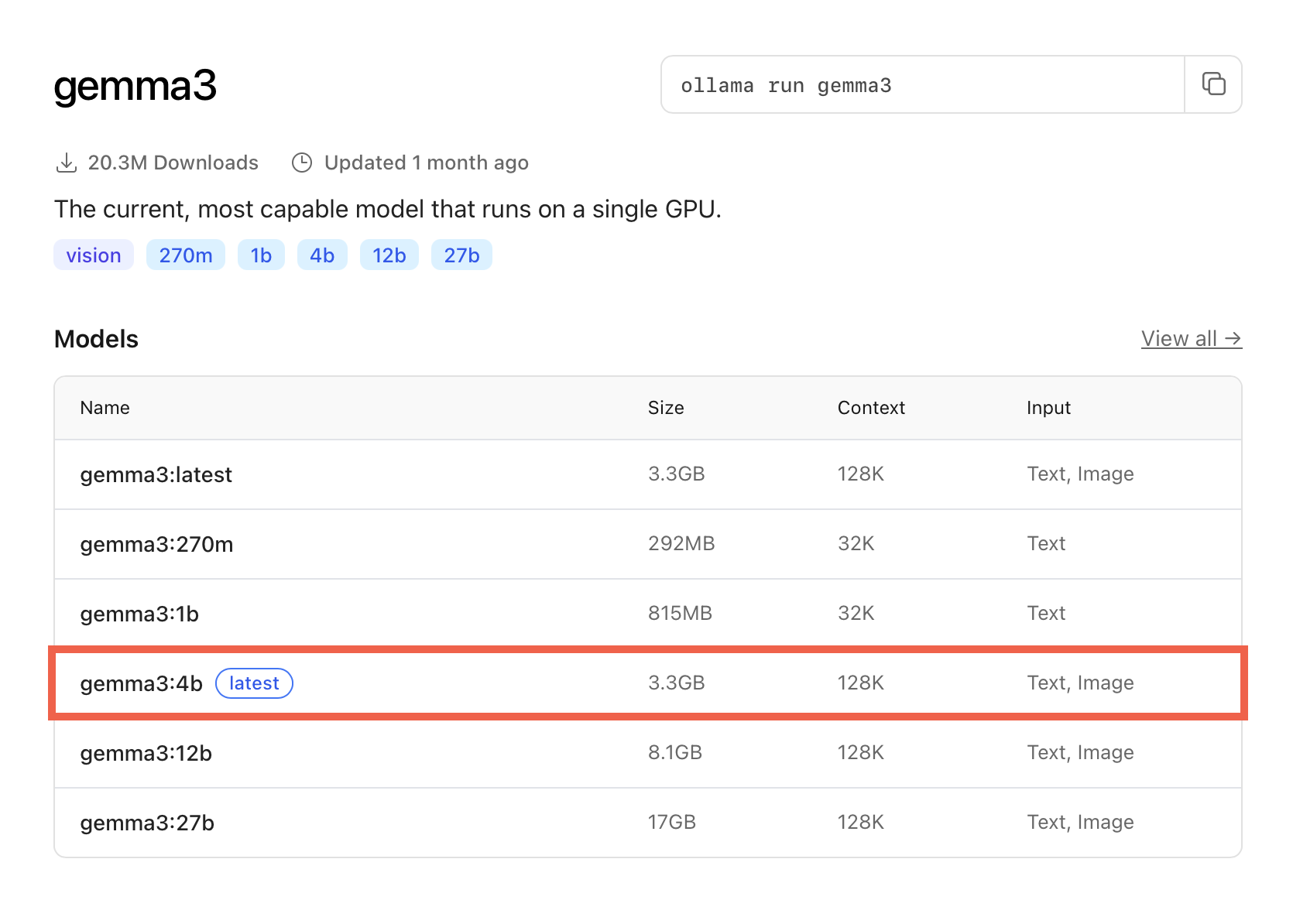
Weiter unten auf jener Internetseite finden sich weitere Informationen. So handelt es sich um ein Modell mit 4 Milliarden Parametern (gekennzeichnet durch „4b“ nach dem Doppelpunkt). Je mehr Parameter ein Sprachmodell hat, desto besser sind die Ausgaben. Allerdings ist zu bedenken, dass mehr Parameter mehr Ressourcen beanspruchen (Arbeitsspeicher, CPU). Deswegen habe ich auch nicht das Modell mit 27 Milliarden Parametern heruntergeladen. Denn der limitierende Faktor bezüglich der Auswahl eines geeigneten Modells ist insbesondere der zur Verfügung stehenden Arbeitsspeicher. Vereinfacht lässt sich sagen, dass ein Modell mit 4 Milliarden Parametern ca. 4 GB Arbeitsspeicher belegt. Bei einem Mac mit 16 GB Arbeitsspeicher stellt ein 4b-Modell kein Problem dar. Anders sieht es mit einem 27b-Modell aus, das so langsam laufen würde, dass die Nutzung absolut keine Freude bereiten würde.
Ein Modell herunterladen, starten oder löschen
Ein Sprachmodell kann mit den Befehlen pull oder run heruntergeladen werden. Der Unterschied besteht darin, dass nach der Ausführung von ollama run <Sprachmodell> versucht wird ein lokales Modell auszuführen. Wenn dieses Modell nicht lokal vorhanden ist, wird es heruntergeladen und anschließend gestartet. Bei der Ausführung von pull wird hingegen ein Sprachmodell nur heruntergeladen. Das Sprachmodell von Mistral könnte also unter Verwendung von pull mit folgendem Befehl heruntergeladen werden, so dass es anschließend lokal zur Verfügung steht.
% ollama pull mistral:7b
pulling manifest
pulling f5074b1221da: 100% ████████████████████████████████████▏ 4.4 GB
pulling 43070e2d4e53: 100% ████████████████████████████████████▏ 11 KB
pulling 1ff5b64b61b9: 100% ████████████████████████████████████▏ 799 B
pulling ed11eda7790d: 100% ████████████████████████████████████▏ 30 B
pulling 1064e17101bd: 100% ████████████████████████████████████▏ 487 B
verifying sha256 digest
writing manifest
success Anschließend wird die Eingabeaufforderung mit dem Befehl run gestartet:
% ollama run mistral
>>> Send a message (/? for help)Wie bereits gezeigt, finden sich auf Ollamas Webseite detaillierte Informationen zu den Sprachmodellen. Im Terminal kann man sie sich ebenfalls ansehen:
% ollama show mistralWenn ein Sprachmodell nicht mehr benötigt wird, hilft rm weiter. Folgender Befehl löscht mistral:7b:
% ollama rm mistral:7b
deleted 'mistral:7b'Ein Modell erstellen bzw. modifizieren
Wenn ihr mit ollama help einen Blick auf die vorhandenen Befehle geworfen habt, mag euch create aufgefallen sein. Was es damit auf sich hat, wollen wir uns nun näher ansehen. In der Dokumentation zu Ollama erfahren wir, dass damit ein Sprachmodell von einem anderen Sprachmodell erstellt werden kann. Im Grunde wird dabei aber nicht ein komplett neues Modell erstellt, sondern ein bestehendes Modell modifiziert.
Dafür erstellt man eine simple Datei, die die Bezeichnung „Modelfile“ haben könnte. Mit einem Editor wie beispielsweise BBEdit, Sublime Text oder Visual Studio Code können in diese Datei nun die Anweisungen für das Modifizieren eines bestehenden Sprachmodells geschrieben werden. Im folgenden Beispiel soll ein modifiziertes Sprachmodell auf Basis des Modells gemma3 erstellt werden. Dieses Modell soll den Namen „Peter“ und der Temperatur-Parameter den Wert 0.6 haben. Außerdem wird dem Sprachmodell eine Rolle zugewiesen. Die Datei Modelfile weist dann folgenden Inhalt auf:
FROM gemma3:latest
PARAMETER temperature 0.6
SYSTEM """
Du bist Peter, ein hilfreicher Assistent auf dem Gebiet der Geschichtswissenschaften. Dein Spezialgebiet ist
die europäische Geschichte. Fragen beantwortest du prägnant und informativ ohne in überflüssige Details abzuschweifen.
Frage stattdessen nach, ob mehr Details gewünscht werden.
"""Für den Temperatur-Parameter können Werte zwischen 0 und 1 angegeben werden. Er legt fest, wie kreativ oder konservativ das Modell auf Eingaben reagiert. Niedrigere Werte führen zu vorhersehbareren Ergebnissen, höhere Werte verleihen den Ausgaben mehr Kreativität. Experimentiert mit verschiedenen Werten, um das gewünschte Gleichgewicht zwischen Kreativität und Genauigkeit zu finden. Ausgangspunkt könnte ein Wert von 0.5 sein, den ihr schrittweise anpasst. Wenn euch die Antworten bei diesem Wert zu ungenau sind, solltet ihr einen noch niedrigeren Wert (z.B. 0,3) einstellen. Stellt ihr hingegen fest, dass die Antworten abwechslungsreicher sein sollen, muss der Wert nach oben korrigiert werden. Ein hoher Wert kann aber eher zu Halluzinationen führen. Bedenkt außerdem, dass die Qualität der Antworten auch durch klare Anweisungen im Systemprompt beeinflusst werden kann. Diese ermöglichen es euch, die Tonalität und den Fokus des Modells weiter zu verfeinern.
Ein Wort der Klarstellung: Häufig wird der Begriff Fine-Tuning in Artikeln oder Videos verwendet, wenn es um das Anpassen von Parametern geht. Dieser Ausdruck ist jedoch irreführend. Fine-Tuning bezieht sich auf den Prozess des Weitertrainierens eines bereits trainierten Modells. Was wir hier tun, ist das Optimieren der Modellparameter durch ein Modelfile, um das Modellverhalten entsprechend unseren Bedürfnissen anzupassen.
Wenn alle Modellparameter zur Modelfile hinzugefügt wurden, ist es an der Zeit, dass modifizierte Sprachmodell unter Verwendung von create zu erstellen, wobei hier davon ausgegangen wird, dass sich die Datei Modelfile im aktuellen Arbeitsverzeichnis befindet:
% ollama create peter -f ./ModelfileNach der Ausführung des Befehls ollama list erscheint nun auch diese Modell (hier: peter:latest):
% ollama list
NAME ID SIZE MODIFIED
peter:latest 1b123e255d2b 7.5 GB 17 hours ago
mistral:latest 6577803aa9a0 4.4 GB 20 hours ago
qwen2.5-coder:latest dae161e27b0e 4.7 GB 7 days ago
gemma3:latest a2af6cc3eb7f 3.3 GB 7 days agoUnser Modell kann nun mit run ausgeführt werden:
% ollama run peterNach dem Namen gefragt, sollte dieses Sprachmodell nun die entsprechende Antwort liefern:
% ollama run peter
>>> Wie heißt Du?
Ich bin Peter, und ich bin spezialisiert auf europäische Geschichte.Ihr könnt nun eine geschichtsbezogene Frage stellen, z.B. „Gib mir eine kurze Zusammenfassung zum Prager Frühling.“ Vielleicht erfüllt das Modell bereits eure Erwartungen und funktioniert wie gewünscht. Sollte dies nicht der Fall sein, könnt ihr in der Modelfile andere Einträge ausprobieren. Hinsichtlich der Modifizierung von Sprachmodellen gilt es experimentierfreudig zu sein. Manchmal wird man auf Anhieb mit dem Ergebnis zufrieden sein, manchmal wird man nachjustieren müssen. Falls euch ein Sprachmodell nicht zusagt, könnt ihr es mit rm löschen und einen neuen Versuch starten.
% ollama rm peterFazit
Ihr habt nun einen tieferen Einblick in die Verwendung von Ollama erhalten. Es gibt aber noch mehr zu erkunden, denn Ollama stellt eine Programmierschnittstelle bereit. Wie diese verwendet werden kann, wird Gegenstand der kommenden Artikel sein. Bis dahin viel Spaß mit dem Erkunden und Modifizieren von Sprachmodellen.
Zum Schluß noch ein Hinweis: Obwohl dieser Artikel speziell auf die Nutzung von Ollama auf macOS fokussiert ist, sind die grundlegenden Prinzipien und Schritte auch auf einem Windows-System ähnlich anwendbar. Die Befehle und Konfigurationen bleiben größtenteils gleich, sodass Nutzer mit Windows lediglich darauf achten müssen, systembedingte Unterschiede in der Terminal-Nutzung zu berücksichtigen. So ist es ganz einfach, die hier beschriebenen Funktionen und Anpassungen plattformübergreifend umzusetzen.
Zuletzt aktualisiert am 30. März 2026